Kafka端到端延迟分析总结
开篇诗两句:
江天一色无纤尘,皎皎空中孤月轮。
江畔何人初见月?江月何年初照人? ——张若虚《春江花月夜》
参考链接:https://www.confluent.io/blog/configure-kafka-to-minimize-latency/
本篇是参考上述文章以及根据实际工作经验总结的Kafka耗时分析。
全链路耗时组成
消息从生产者发送到Kafka集群之后,再到消费者从Kafka集群中拉取消息,整个链路的耗时可以拆分成如下几个部分:
- 生产耗时:生产者内部处理消息,将消息和其他消息组装成batch的耗时
- 发送耗时:生产者将消息发送到Broker集群的耗时
- 提交耗时:follower从leader同步数据的耗时
- 追赶用时:当前消费offset追赶到生产offset的耗时
- 拉取耗时:从Broker集群拉取消息的耗时
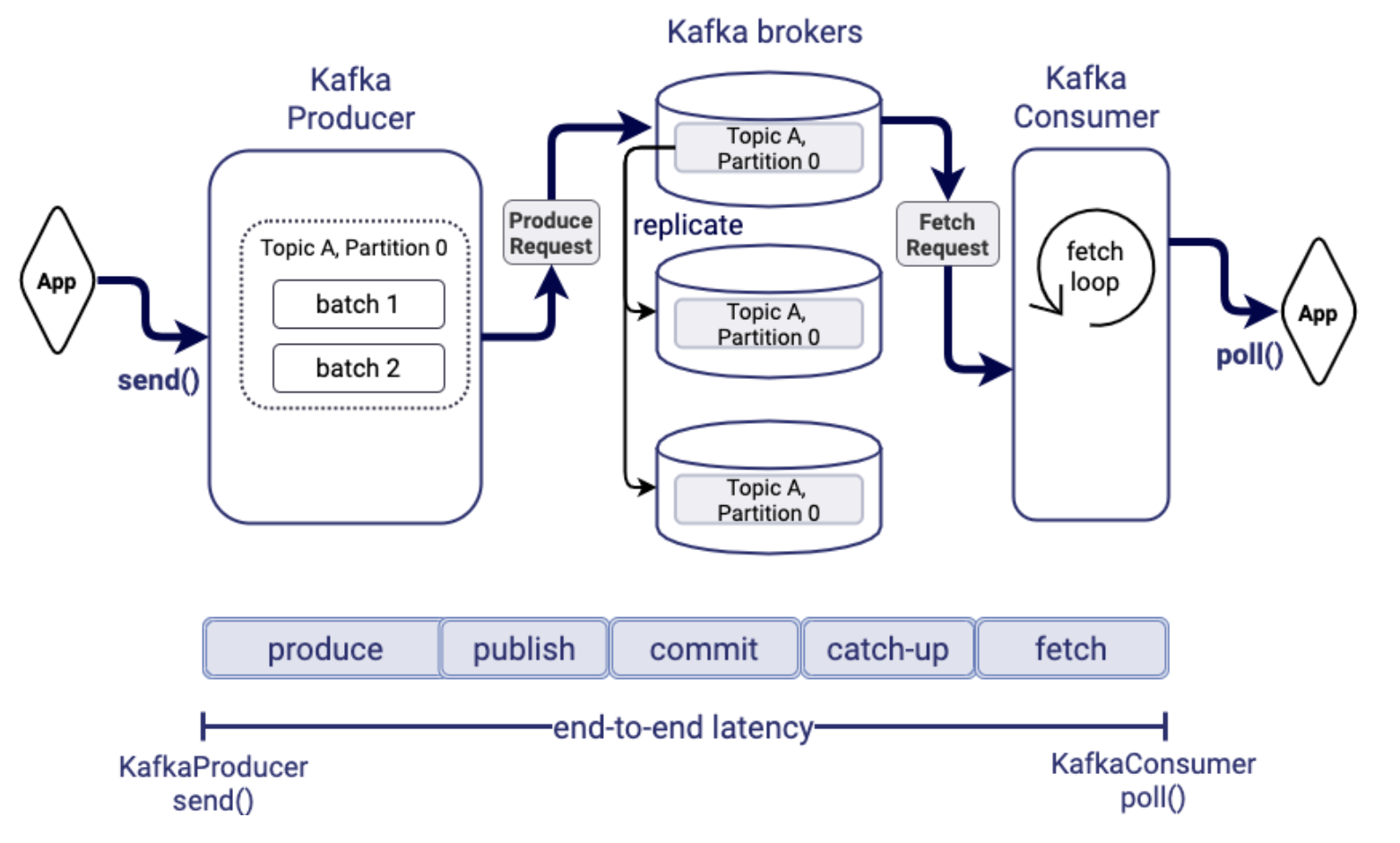
下面详细分析各个阶段耗时的影响因素。
生产耗时
在Kafka的配置中,影响生产耗时的配置主要有如下三个:
- linger.ms:batch组装等待时间
- batch.size:每个batch的大小
- max.inflight.requests.per.connection:每个链接最大未完成请求的数量
Kafka的生产者在发送消息之前,首先会将消息组装成batch之后在进行发送,针对batch有两个配置,就是linger.ms和batch.size,当前的batch等待linger.ms时间或者batch的大小达到batch.size,就可以进行发送了。
由于不同的partition之间的batch是单独组装的,所以当生产数据量不是很大的情况下,过多的partition数量可能会导致发送耗时上升。过多的partition数量导致每个partition的batch都不能快速的满足batch.size,导致每次发送都要等待linger.ms时间,而partition数量较小时,batch可以很快组装完成,进而快速发送出去。
max.inflight.requests.per.connection是限制同一个链接最多允许存在多少未完成的请求,所以为了保证发送速度,需要保证Broker集群能够快速ack生产请求。
此外,Kafka还支持配置压缩方式,compression.type配置。不同的压缩方式能够改变消息发送的数据量,进而影响消息的发送速度。
发送耗时
发送耗时主要是之生产者发送消息到partition的leader副本的耗时。
主要由 网络耗时 + requestQueueWaitTime + 消息写日志耗时 + responseQueueWaitTime 组成。其中网络耗时主要取决于网络状况,写日志耗时主要取决于Kafka写日志文件的方式,直接写PageCache,由操作系统负责落盘。这里主要说一下requestQueueWaitTime,请求队列等待时间。
请求队列等待时间主要与Broker的负载有关,Broker上所有的请求都是通过一个RequestHandler的线程池来处理,默认是8个线程。Kafka网络层接到生产者发送的请求之后,会将请求放到请求队列中,由RequestHandler线程池逐一处理。因此,当生产请求的QPS过高时,RequestHandler线程池出现瓶颈,会导致整体的发送耗时上升,其中很大部分的耗时是在请求队列中的耗时。此外,由于RequestHandler线程池是处理所有的请求,所以消费请求的QPS过高同样会影响发送耗时,而且除了影响发送耗时外,副本同步耗时,消费拉取耗时都会影响,这个之后会说。
针对RequestHandler线程池瓶颈导致的发送耗时升高的情况,目前工作中采用的方式基本就是集群扩容。不过适当增加RequestHandler线程池的线程数量,理论上也是可以增加处理能力的,但是实际场景没试过。
提交耗时
提交耗时主要指follower副本从leader副本同步数据的耗时。在ack为-1的场景的下,只有ISR中的follower都完成数据同步之后,Broker才会ack发送请求,所以发送请求的耗时是从消息生产,到Broker完成ack响应的总时间。
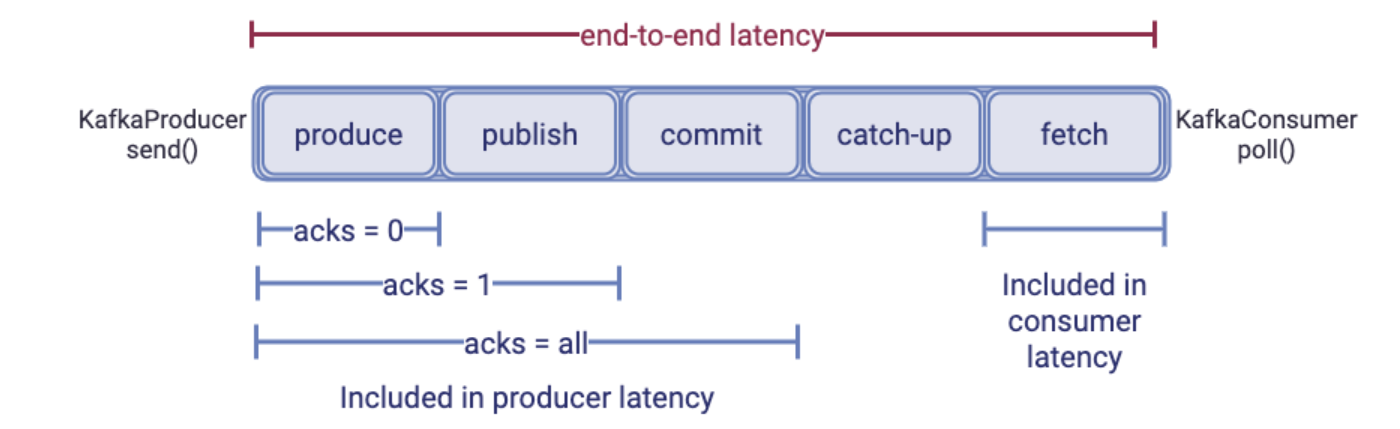
同时,消费者也只能拉取提交之后的消息(所有ISR副本同步完成之后的消息)。
提交耗时主要取决于最慢follower副本同步数据的耗时,该部分也是在ack为-1的场景下,对发送耗时影响最大的部分。
配置参数
副本拉取有两个参数配置,replica.fetch.min.bytes和replica.fetch.wait.max.ms
- replica.fetch.min.bytes:每次拉取请求最小拉取字节数
- replica.fetch.wait.max.ms:每次拉取请求最长等待时间
副本拉取请求满足上面两个配置中的任意一个就会返回,replica.fetch.min.bytes配置我们设置的是1,保证最快拉取,但是该配置设置的过小,带来的问题是虽然能够保证拉取请求快速响应,但是在某些场景下可能会增加Broker负载,频繁的数据同步请求,但是每次只同步很少量的数据。
分区数量
Broker之间进行数据同步的时候,是一个fetch请求拉取所有leader副本的消息,所以带来的问题有三个:
- 每次fetch请求需要遍历过多数量的分区,导致fetch请求的耗时增加
- fetch请求是每个分区最多拉取1M的消息,分区数量增多,导致fetch请求的处理的数据量增加,进而增加fetch请求的处理时间(高版本kafka增加了fetch请求最大拉取消息大小的总量配置,测试高版本踩过的坑。。。)
- 分区数过多带来的近似随机读磁盘的问题,影响读磁盘耗时(与PageCache使用有关,暂时忽略该影响)
fetch请求的处理耗时增加,必然导致发送耗时增加。此外,因为是一个fetch请求处理所有的分区,所以必然存在分区之间数据量不同带来的分区之间的相互影响。
可以试想一下,当一个集群只有一个小流量分区时,数据同步的fetch请求可以很快处理完成,发送耗时也相对较低。但是当增加一个流量比较大的分区,导致同一个fetch请求需要同时处理大流量分区和小流量分区,导致fetch请求处理的数据量增加,处理耗时增加,从而导致小流量分区在不进行任何操作的情况下,发送耗时上升。该情况其本质与增加分区数量带来的fetch请求处理耗时增加的场景类似。
针对这个问题,之前考虑过修改Broker之间数据同步的网络层模型,各个分区之间采用异步处理的方式,解除各个分区间的数据同步的耦合关系,后来发现快手已经做过类似的修改,具体修改之后的效果,没有使用过,不是很清楚。
此外为了增加数据同步的并行度,可以调整fetcher线程的数量,但是也会存在问题,下面来说一下fetcher线程数量的相关问题。
Fetcher线程数量
一定程度增加Fetcher线程数量对于提高副本同步速度是有效果的,但并不代表增加fetcher线程数量一定是有利的。Broker集群的fetcher线程是节点粒度的,当每个节点启动1个fetcher线程时,对于10台机器的Broker集群,每个Broker节点需要启动9个fetcher线程用于数据同步。
因此,增加fetcher线程数量带来的问题,就是针对大集群,例如60个节点的Broker集群,fetcher线程数量从1变为2,每一台Broker的fetcher线程就会从59变为118个,导致每个节点为了数据同步启动大量的同步线程,会对CPU调度带来非常严重的影响,甚至严重影响Broker整体性能。
而且通过实测来看,增加fetcher线程数量与提高同步速度带来的收益不成正比,数量越高,收益越低。
请求QPS
上面说发送耗时也提到过,Broker处理所有的请求都是通过RequestHandler线程池来处理的,fetch请求也不例外,所以当请求量过高,包括生产请求和消费请求,都会导致fetch请求在请求队列中的等待时间增加,进而导致同步速度变慢。
这个问题之前也有考虑为数据同步请求采用单独的RequestHandler线程池,避免fetch请求与生产和消费请求相互竞争,影响同步速度,但是该想法还没有实现,尚不知道效果如何。
数据空拉
实际生产环境中,会存在很多无流量分区,而对于kafka的fetch请求还是会遍历这些没有数据的分区,导致数据空拉的情况。我们针对这个情况,修改了数据同步时的拉取逻辑,只遍历有增量数据的分区,一定程度上减少fetch请求的处理耗时。
消费请求的影响
在工作中进行读写节点分离的方案设计和测试中发现,消费请求对follower副本进行数据同步也存在影响。从线程模型上分析,消费请求和发送fetch请求以及处理fetch请求的response都是线程隔离的,所以理论上不应该存在很明显的影响,但是在实际测试过程中发现,大量的消费请求也会影响follower副本发送fetch请求或是处理fetch请求的响应,期间CPU指标没有明显变化,可能与磁盘操作有关,具体原因还没确定,之后有时间再分析吧。
追赶耗时
所谓追赶耗时就是消费者消费的offset追上生产offset的耗时,即处理积压消息的耗时。这部分耗时主要取决于后面要说的拉取耗时和消费者处理消息的消费逻辑耗时。
在消费速度完全能够跟上生产速度的情况下,这部分耗时几乎为0。

拉取耗时
拉取耗时与发送耗时类似,由 网络耗时 + requestQueueWaitTime + + 读取消息耗时 + responseQueueWaitTime。
requestQueueWaitTime的耗时与发送耗时类似,当请求量过大时,请求队列的等待耗时会增加。
此外,拉取请求有两个相关的配置fetch.min.bytes和fetch.max.wait.ms。
fetch.min.bytes默认设置的时1,保证快速返回,fetch.max.wait.ms默认设置的时500ms。