G1垃圾回收机制
开篇诗两句:
春眠不觉晓,处处闻啼鸟。
夜来风雨声,花落知多少。 ——孟浩然《春晓》
学习G1收集器过程中总结的相关知识。
概述
G1(Garbage First)是当今垃圾回收机制中最前沿的成功之一,在JDK7中就已经开始引入G1,并作为重点发展的垃圾回收器。G1最大的特点是引入了分区的思想,一定程度上弱化了分代的概念,同时解决和很多其他收集器存在的缺陷。
GC收集器回顾与比较
当前JVM主流的收集器如下:
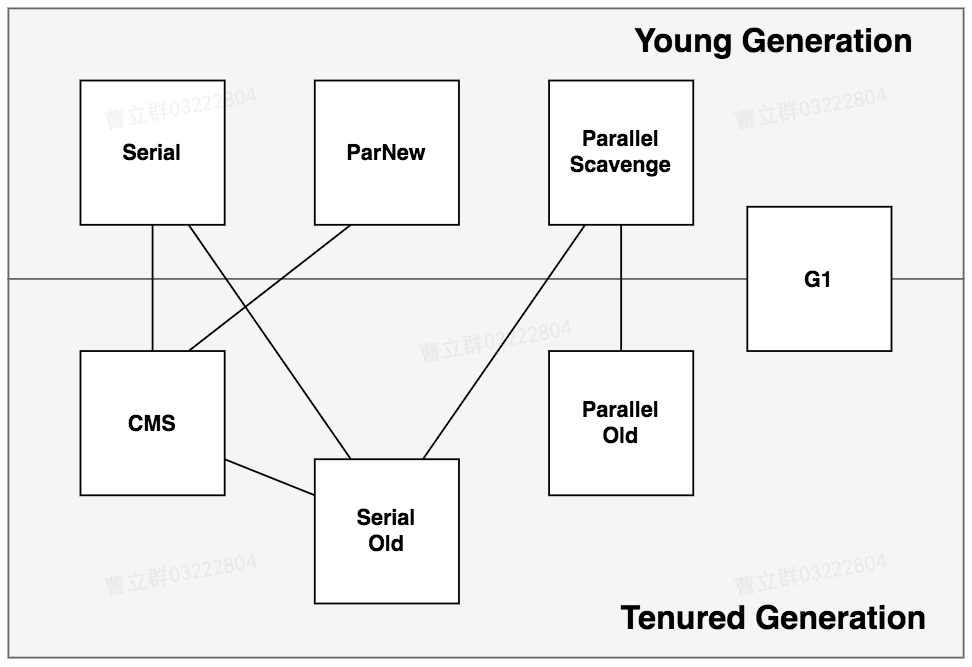
各个收集器对比:
| 收集器 | 组合 | 流程图 | 优劣势 |
|---|---|---|---|
| 串行收集器 | Serial + Serial OldSerial用于回收新生代 Serial Old用于回收老年代。 |
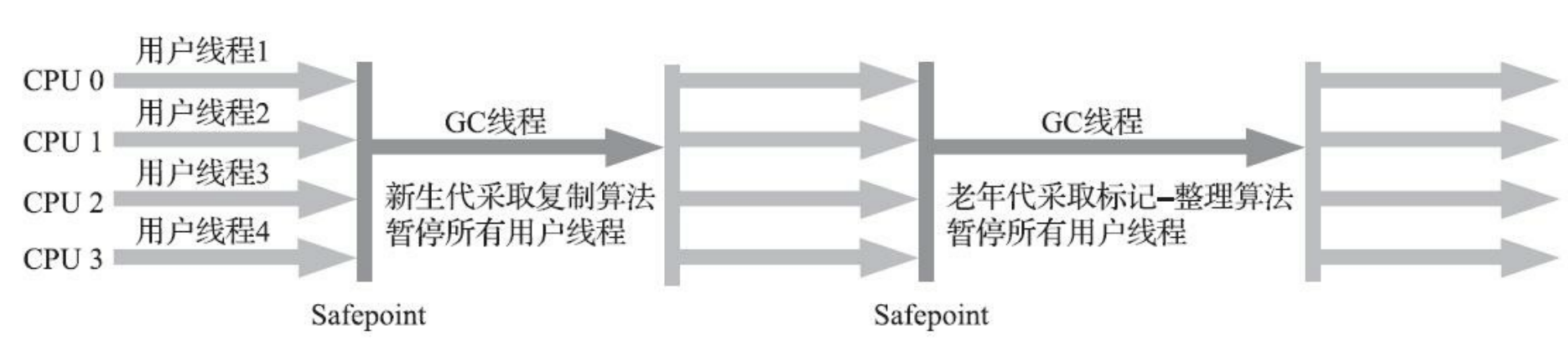 |
优势:由于串行收集器采用的是单线程的处理方式,所有复杂度更低,占用内存少 劣势:回收速度不高,STW(Stop The World)导致应用停顿时间过长。 |
| 并行收集器 | Parallel Scavenge + Parallel Old Parallel Scavenge回收新生代 Parallel Old回收老年代 |
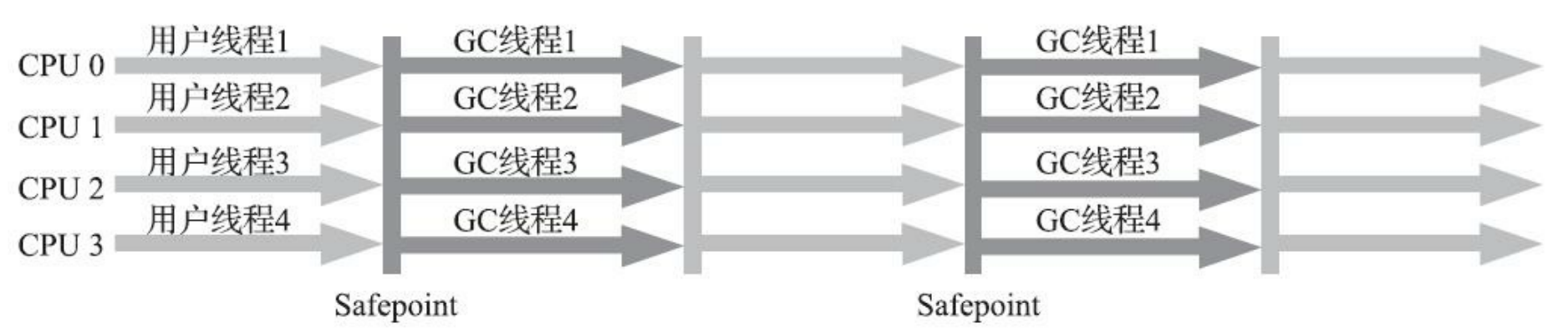 |
优势:GC过程是多线程并发执行,回收速度相对于串行收集器更快,适合高吞吐场景 劣势:占用资源相对于串行收集器要更多一点,并且不适合延迟要求高的场景 新生代:复制整理算法,老年代:标记整理算法 本身是追求高吞吐的收集器 |
| CMS | ParNew + CMS + Serial Old ParNew回收新生代 CMS回收老年代 Serial Old兜底策略 |
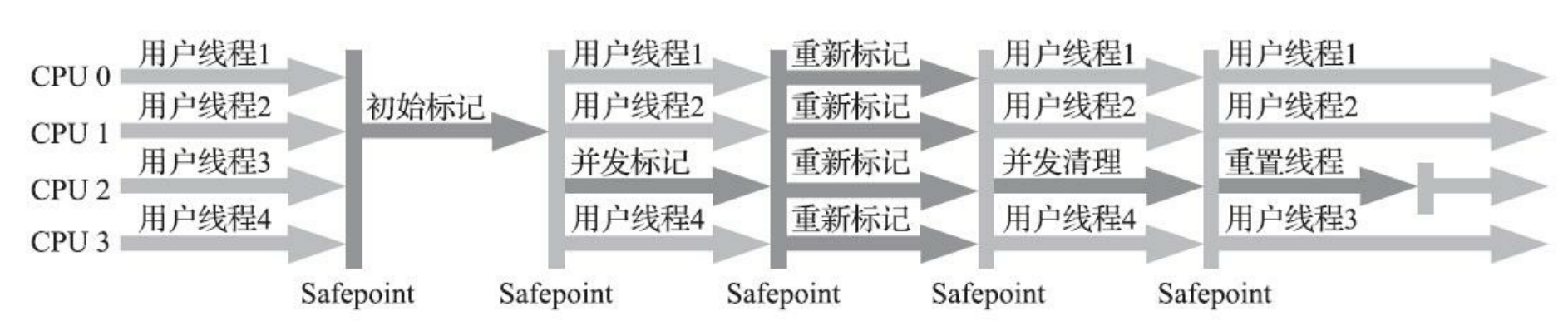 |
优势:GC过程是多线程执行,以关注延迟为目标 劣势:吞吐量方面不如并行收集器CMS在进行内存回收时会增加堆内存的使用量,所以CMS进行回收时,必须要在老年代堆内存用尽之前,否则就必须通过Serial Old进行串行回收,导致更大的停顿CMS使用的时标记清除算法,会产生内存碎片 新生代:复制整理算法,老年代:(1)初始标记(STW)(2)并发标记(3)重新标记(STW)(4)并发清除 |
| Garbage First | Garbage First即收集新生代,又收集老年代 | 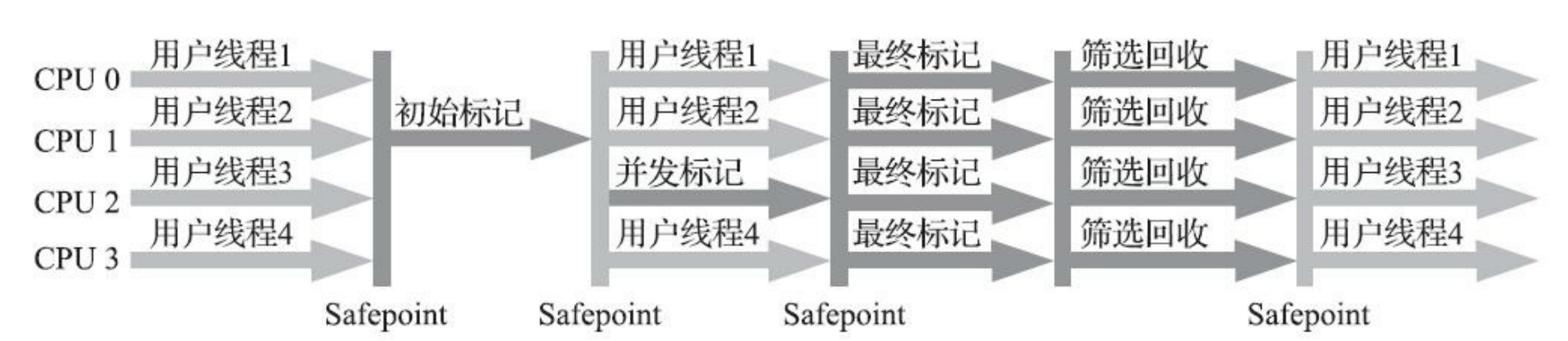 |
优势:以关注延迟为目标,引入分区思想,进一步降低延迟时间,同时解决CMS内存碎片的问题 劣势:需要更多的内存来完成内存回收,如果内存不足,同样需要使用串行回收作为兜底策略 |
G1内存模型
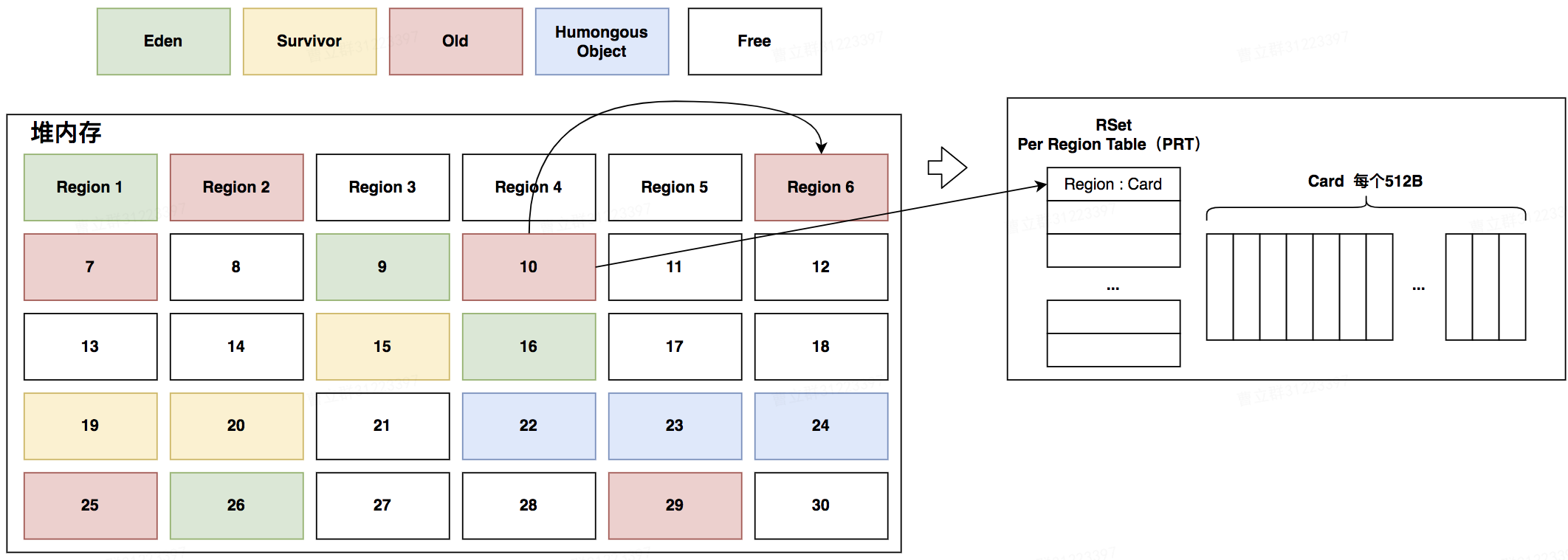
相关概念
| 概念 | 描述 |
|---|---|
| 分区 (Region) |
(1)G1引入了分区的思想,将堆内存划分为多个Region(1M ~ 32M,可以配置) (2)G1同样使用新生代和老年代的概念,但是与CMS不同的是,新生代和老年代不再使用连续的逻辑地址,而是新生代和老年代都会对应一个分区集合,这些分区之间不需要连续的逻辑地址 (3)每个Region不会确定为新生代或老年代服务,随着执行时间,Region所属的代会变化 |
| 卡片 (Card) |
(1)每个Region内部会划分成多个Card,每个Card默认时512B,可以配置 (2)实际内存分配,内存回收都是按照Card粒度执行的,对象会占用连续的Card |
| RSet (Remember Set) |
(1)记录谁引用了当前Region内对象(指针) (2)RSet有三个级别:稀少,细粒度和粗粒度,在回收当前Region时,通过RSet获取需要扫描的Region来判断当前Region中存活的对象 |
| CSet (Collection Set) |
(1)每次GC收集的分区集合,GC之后,CSet中的所有分区都会备回收,存活对象会复制到新的空闲的Region中 (2)Young GC时,CSet只包含新生代的Region,Mixed GC时,CSet中既包括新生代Region,也包括老年代Region,本质上新生代和老年代GC回收的处理方式是相同的 |
| TLAB (Thread Local Allocation Buffer) |
新生对象都分配到Eden区中,Eden是全局的概念,所以进行内存分配的时候会对Eden区进行加锁,增加强锁的耗时TLAB是指每个Thread都会有一个Eden区独占的Region进行内存分配,减少抢锁的情况出现,如果对象超过Region大小,还是会分配到全局的Eden区的Region中,还是需要进行加锁 |
| PLAB (Promotion Thread Local Allocation Buffer) |
与TLAB类似,TLAB是应用线程,PLAB是GC线程独占的Eden区的Region,GC线程在进行survivor区拷贝时,就会向自己的私有缓冲区拷贝,目的还是减少并发抢锁带来的耗时 |
YoungGC流程
Young GC需要STW(Stop the world)
| 名称 | 描述 | 结构图 |
|---|---|---|
| 选择收集分区集合(CSet) | Young GC过程的CSet会包括所有的年轻代分区。 | 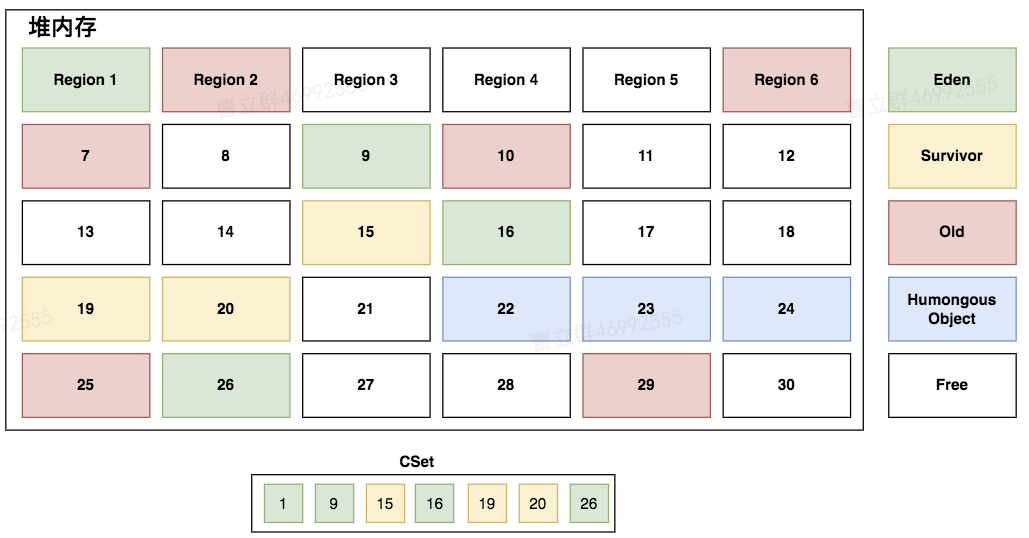 |
| 根扫描 | 通过Root判断CSet集合中的分区中哪些是存活对象(包括整个引用路径) | 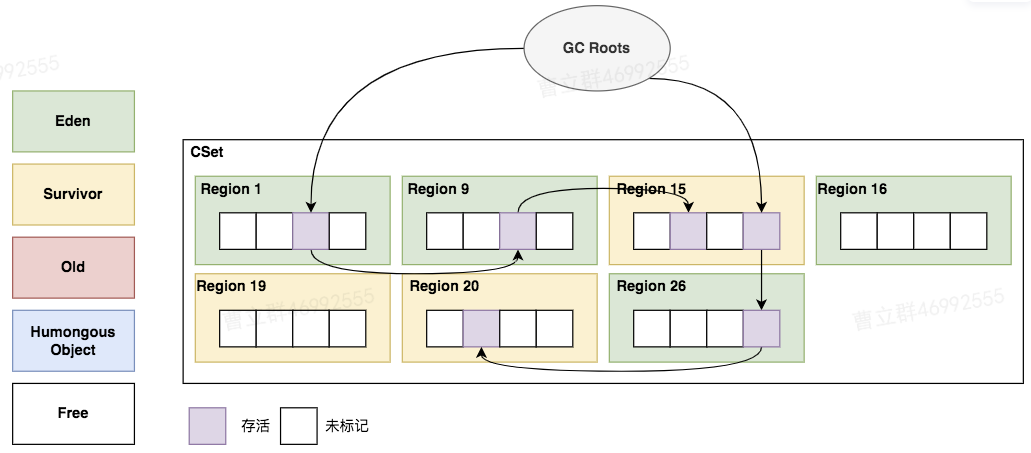 |
| RSet扫描 | 更新RSet,应为RSet的更新是异步写入的,所以需要保证RSet是最新的,见7.2 通过Region中的RSet判断有哪些对象被引用,并标记成存活对象(包括整个引用路径) |
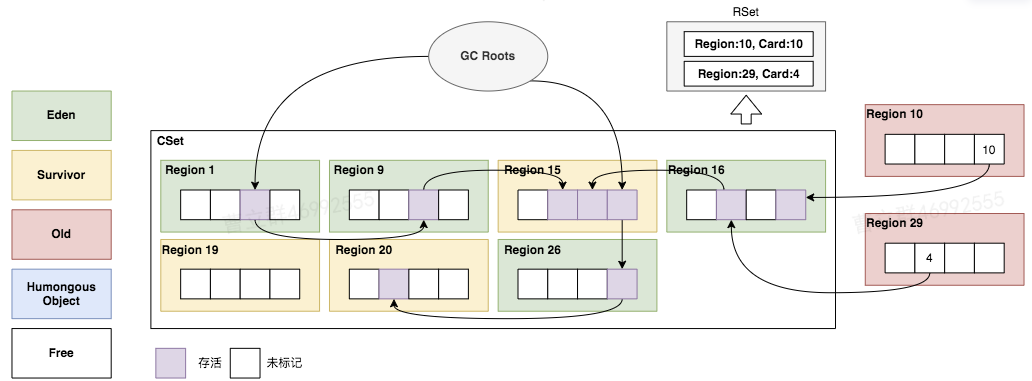 |
| 复制整理 | 将步骤2和步骤3标记的存活对象复制到新的survivor分区中GC线程在进行对象复制时 不是所有GC线程都向同一个Region复制,而是复制到自己的私有缓冲区中(PLAB) |
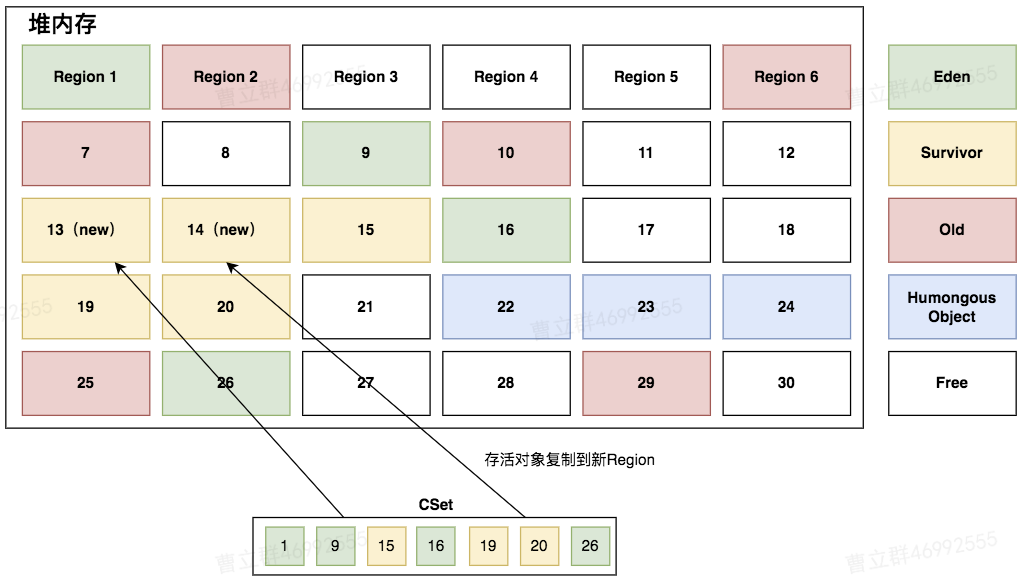 |
| 释放分区 | 将原本年轻代的分区全部释放 | 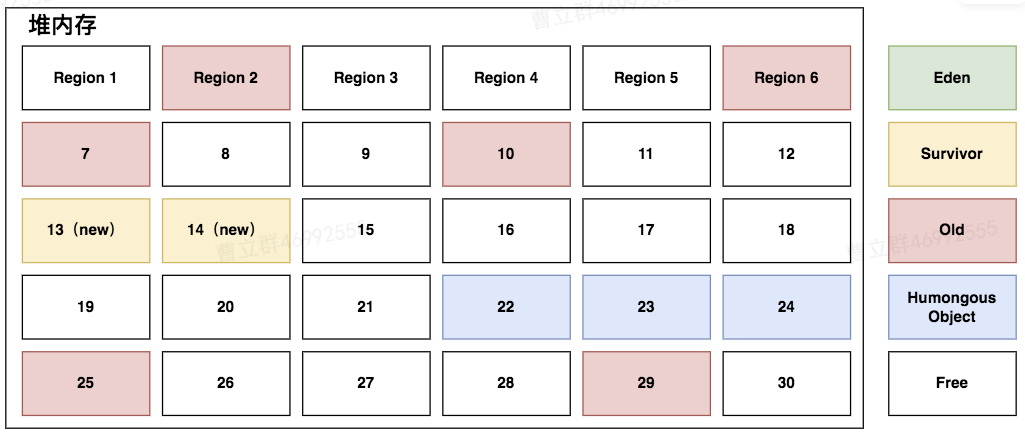 |
MixedGC流程
Mixed GC主要分为如下几个阶段:
(1)初始标记(2)根分区扫描(3)并发标记(4)重新标记(5)清理(6)内存回收
初始标记(Initial Marking)
初始标记的目的:标记所有root object
当 Old Generation 空间占用整个 Heap 比例超过目标值(-XX:InitiatingHeapOccupancyPercent, IHOP)后,开始 OGC 过程,最开始执行的是初始标记阶段。
但是不是触发IHOP之后就立刻执行初始标记,而是等待下次Young GC执行时,同时执行初始标记。
因为初始标记需要STW,所以为了减少暂停时间,初始标记会和young GC同时执行(young GC同样需要STW)
根分区扫描(Root Region Scanning)
扫描Young GC过程拷贝到survivor区的所有对象,并标记为live (Young GC存活下来的对象都认为是live对象)
该阶段需要在下一次Young GC执行之前完成,否则该阶段执行失败需要重新执行(survivor中的对象变化,需要重新扫描)
并发标记(Concurrent Marking)
并发标记目标:标记所有存活对象
并发标记线程每次扫描一个Region,并根据Region的RSet来标记Region中存活对象(标记在一个全局的Bitmap中)
并发标记线程还会定时消费SATB缓冲区,标记存活对象(见Pre-Write Barrrier)
重新标记(Remark)
重新标记阶段需要将SATB缓冲区消费干净,并且处理完成所有其他的引用更新,找出所有未被标记的存活对象。因为如果应用线程持续运行,引用信息会持续变化,所以该阶段也是STW的
清理(Clean)
该阶段不是真正执行内存回收的阶段
(1)根据每个Region的garbage占用情况,和RSet活跃程度评估每个Region的GC效率,并根据GC效率将Region排序。
(2)发现没有存活对象的Region时直接将其清理。
(3)对每个Region的RSet进行清理,比如发现一个card中指向当前Region的Object都dead了,就直接清理这个RSet内的记录。因为之后无论是YGC还是Mixed GC都会扫描这个RSet,将其清理一下有助于提升之后清理过程中RSet扫描效率。
内存回收(Mixed GC)
Mixed GC本质上就是Young GC,通常Young GC时CSet(被回收分区的集合)只会包含新生代Region,但是Mixed GC时,CSet中会添加老年代的Region,实际回收方式都是一样的(复制整理)。
RSet记录与更新
并发标记阶段在标记所有存活对象时,需要扫描每个Region的RSet表,来判断有哪些Region的Card引用了当前Region,以此来判断当前Region中的存活对象。
RSet的主要作用是记录有哪些Region引用了当前Region中的对象,减少在GC过程中标记对象时扫描的内存大小,进而减少GC过程的停顿时间。
RSet记录
RSet会根据分区引用活跃度(其实就是引用数量)分为三个等级,每个等级都有会一个PRT表来存储相关内容:(1)稀少(2)细粒度(3)粗粒度
(1)稀少
该等级的RSet会直接记录引用当前Region的Card的指针(Region : Card)
通过这种方式,当需要回收当前Region时,只需要根据RSet中记录的指针,扫面对应的Card来判断当前Region中存活的对象即可。
(2)细粒度
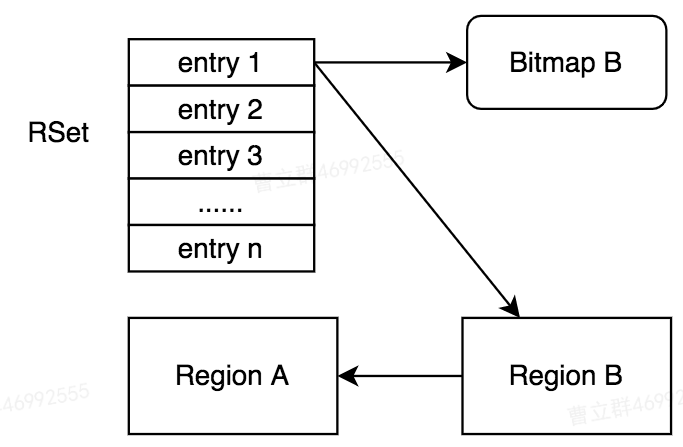
该等级中的RSet不再直接保存Card的指针,而是为Region B创建一个位图(Bitmap B),然后A中的RSet中保存该位图和Region B的指针。
Bitmap B中每个Bit表示Region B中的一个Card,通过这种方式记录Region B中各个Card对Region A的引用关系。
这种存储方式相较于上面稀少等级,需要占用更多的存储空间,而且是间接保存的引用关系,所以扫描耗时会相对更长。
(3)粗粒度
该等级的RSet本身就是Bitmap,Bitmap中每个Bit代表堆内存中的一个Region,通过这种方式保存其他分区对当前分区的引用关系。
这种方式带来的缺点就是,需要扫描整个Region才能找到各个Card的引用关系,耗时会更长。
RSet更新
RSet更新是通过写栅栏(write barrier)实现的。其中G1实现了两个barrier,(1)pre-write barrier (2)post-write barrier
(1)写前栅栏(pre-write barrier):写前栅栏不是用来更新RSet,具体见并发标记流程
(2)写后栅栏(post-write barrier):
该post-write barrier在每次写入引用时都会被调用,但是实际应用修改引用的频率非常多,所以该barrier必须保证性能。post-write barrier只作如下两件事:
(1)判断当前写入的reference是不是跨Region的(当前Region引用当前Region内部的对象是不需要记录到RSet中)
(2)判断是不是old-to-old,old-to-young(young-to-old,young-to-young是不记录的)
如果满足上面两个条件,就会将引用修改的相关信息(引用所在的Card,被引用的Region等信息)写入到update log buffer中(可以简单认为是一个队列),如果当前update log buffer写满了,会重新申请一个新的update log buffer,并将原有的放入到全局的list中。
之后会有concurrent refinement threads去消费update log buffer,并更新对应Region的RSet信息,以及RSet粒度调整的相关工作。
concurrent refinement threads是可以多线程并发执行的,具体数量是根据update log buffer中积压的情况动态调整的,但是concurrent refinement threads的数量不是无限增大的,当update log buffer堆积的数量过多导致消费不完时,此时应用线程会协助concurrent refinement threads来完成RSet更新操作,此时会影响应用线程的效率。
标记流程
G1 的这套 Marking 算法借鉴了Snapshot-at-the-beginning (SATB) 算法
SATB 内部会对 Heap 维护一个 Snapshot,标记工作也是在这个 Snapshot 上进行。SATB 保证:
对象和参数介绍:
(1)PrevBitmap,NextBitmap
SATB 会维护两个Bitmap,PrevBitmap和NextBitmap。PrevBitmap存的是上一次完成的标记信息,当前标记阶段会创建并更新NextBitmap。随着标记阶段的进行,NextBitmap会逐渐被完善,当NextBitmap拥有整个堆的标记信息后,NextBitmap会替代PrevBitmap。
(2)top-at-mark-start (TAMS)
在 G1 Region上,有两个top-at-mark-start (TAMS) 标记位,一个是标记上一次标记阶段使用的TAMS,也称为PrevTAMS;另一个用来标记本次标记阶段,也称为NextTAMS。
SATB算法执行流程
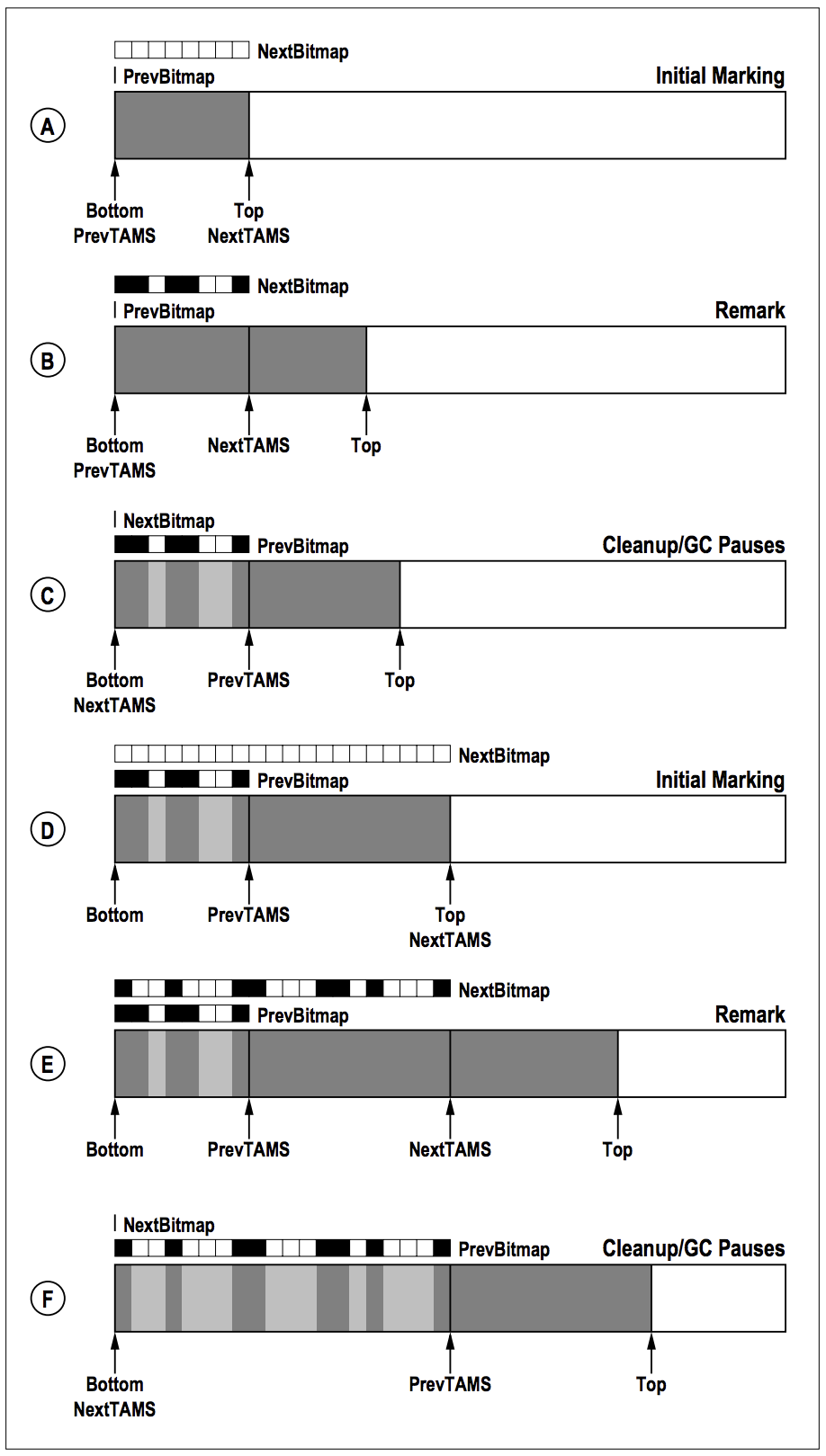
阶段A:
(1)PrevBitmap和NextBitmap都是空的,说明这是个新Region,没有经历过标记阶段。
(2)Bottom和Top之间是Region当前已经分配的空间。
(3)因为没有经历过标记,PrevTAMS指向 Bottom。NextTAMS不管Region之前是否经历过标记,initial marking的时候都会指向Top。
阶段B:
(1)在Remark阶段结束之后,来到了图中B指示的阶段。
(2)NextBitmap已经被标记了哪些是存活对象。
(3)NextTAMS到Top之间的object是并发标记阶段,因为业务线程跟标记线程并发运行而新产生的 object。这部分object全部认为是live的。(只针对PrevTAMS到NextTAMS之间的区域进行标记)
阶段C:
(1)Clean阶段,NextBitmap替换PrevBitmap
注意:NextBitmap和PrevBitmap 实际都是全局的一个Bitmap,是标识整个Heap的。上图中Bitmap看上去跟Region绑定只是为了方便看,便于理解。
阶段D:
(1)G1的Mixed GC不是一定要在整个Heap上所有dead object都被收集干净了才停止,而是只要根据标记提供的dead object占用的空间在整个Heap中占比小于一定值后,就停止收集。所以完全是有可能存在能经历两次甚至更多次标记的Region。
(标记整理,正常被回收的Region会被整体释放掉)
(2)从D能看到Top相对于C增长了一些,说明上次标记结束后,这个Region上又有新晋升上来的object。
(3)跟A一样,PrevBitmap、PrevTAMS保持不变,创建NextBitmap,NextTAMS指向Top。并且看到PrevBitmap没有变化,因为不经历标记这个bitmap是不可能变化的。
阶段E:
(1)跟B一样,Remark结束,Bottom到NextTAMS之间所有存活的object都被标识出来
(2)NextTAMS到Top之间是本轮并发标记阶段新晋升的object,直接被标记为live。
阶段F:
(1)跟C一样,NextBitmap替换PrevBitmap,NextBitmap被清理。
从上面看到标记阶段实际就是为了维护PrevBitmap,通过这个Bitmap,就能知道一个Region上有多少存活object,从而能够根据dead object空间占比来排序,找出GC效率最高的Region来GC。
写前栅栏(pre-write barrier)
写前栅栏只会在并发标记阶段生效,而写后栅栏是持续生效的
例如如下伪代码:
//java 代码
x.f = y
//pre-write barrier
if (is-marking-active) {
prev = x.f;
if (prev != Null) {
satb_enqueue(prev);
}
}
写前栅栏会将被删除的引用投递到SATB缓存区中,然后由concurrent marking thread(并发标记线程)消费,将被删除引用的对象标记成live状态。
写前栅栏主要解决的问题是,防止出现漏标的情况出现:
例如:
x.f = z // 假如一开始 x.f 是指向 z 的
x.f = y // 修改 x.f 的引用,此时 z 可能确实是死掉了
w.f = z // 由于某种原因将 z 救活
此时由于应用线程和标记线程是并发执行的,如果没有写前栅栏,很可能会将z标记成dead状态,并在之后将z回收,导致问题出现。
写前栅栏的原则:宁可错标也不能漏标。
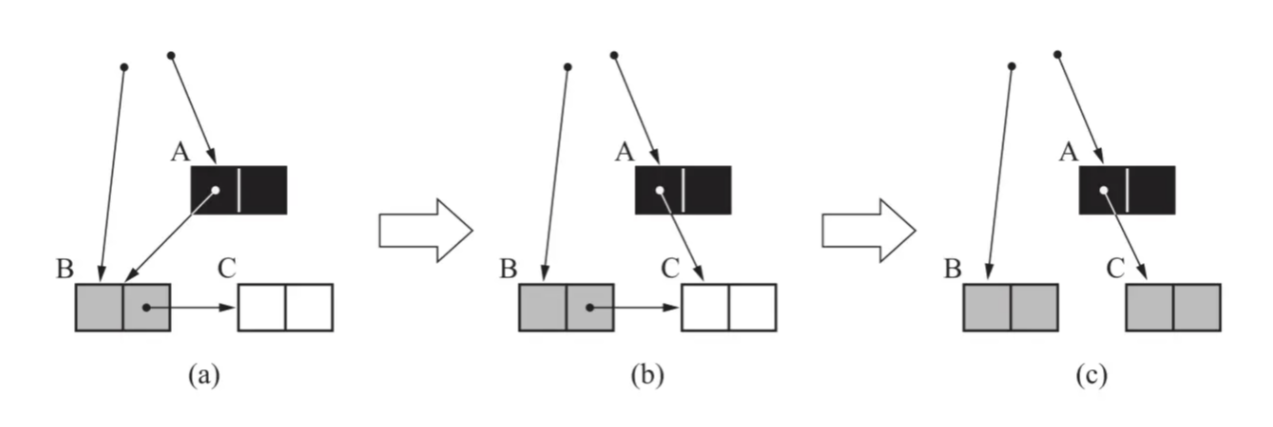
三色标记法漏标记的情况:
(1)没有写前栅栏,可能出现漏标记的情况:
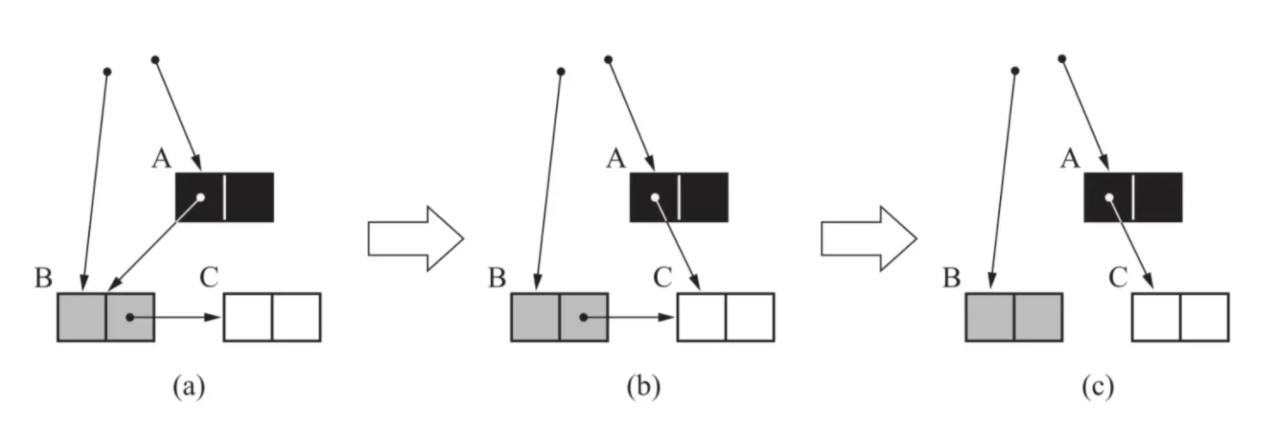
(2)增加写前栅栏后,当移除B对C的引用后,会将C标记成存活状态